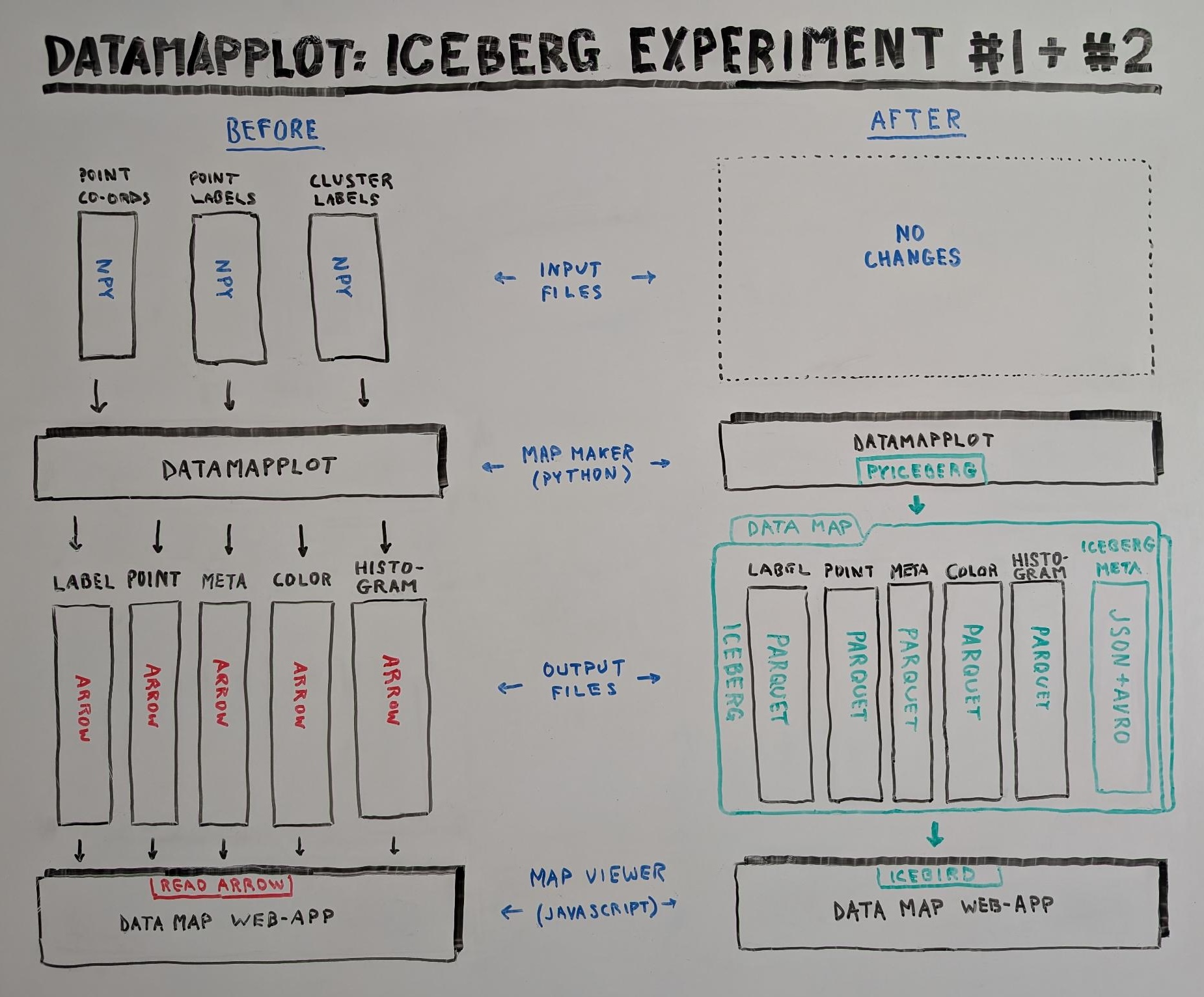
DataMapPlot generates interactive data map viewer web apps; think Google Maps but for some imaginary latent-space landscape. The data used to render the maps is currently shipped over HTTP as zipped Arrow files (in red in the image below).
The proposal herein is to try another Apache file technology, Iceberg (in green below), which might immediately perform better than Arrow over the web. If that turns out to true then as a corollary this upgrade would set up DataMapPlot for easy integration within the Iceberg ecosystem.
A two step plan
The first two “DataMapPlot meets Iceberg” experiments that come to mind are a one-two combo, the second building on the first:
- Migrate from the current zipped Arrow files to Parquet files
- Package those Parquets in an Iceberg file-and-folder structure, along with some trivial Iceberg metadata files.
Note that these first experiments involve no changes to DataMapPlot’s input files, the only modification is to the data files passed over the web between the Python engine and the JavaScript engine.
Experiment #1
Currently, DataMapPlot writes data map info to Arrow files which are then zipped. Those are solid weathered technologies, but perhaps Parquet can provide additional benefits. An immediate one that can be expected is smaller data map files.
Apache Iceberg stores data in Parquet files. So, the first step in Iceberg-ification is: Arrow => Parquet. This will involve a file format change, nothing more: a goal is to keep the existing tables structured as-is, but the files will be formatted as Parquet.
If the above proves valuable (say, faster parsing and smaller data files at the cost of around 100KB more code in the web-app), that alone is arguably valuable.
Experiment #2
If the above first experiment goes well, then the next step is to become minimally Iceberg formatted. In other words, first “adopt Parquet” in Experiment #1 then in Experiment #2 “adopt Iceberg.”
This will simply involve packaging the Parquet tables from Experiment #1 into an Iceberg database (a specific folder tree with a properly populated metadata folder). The goal is to have DataMapPlot’s Python generate Apache Iceberg and the in-browser JavaScript to read those Icebergs.
The data changes:
- (Experiment #1 already changed Arrow to Parquet)
- Move all generated data files (now Parquets) into directory data/ and its subfolders
- Add directory metadata/
- In metadata/ add three metadata files (one JSON and two Avro)
Code changes:
- Python: add PyIceberg to write to Iceberg tables
- JavaScript: Icebird to read Iceberg
Conclusion
The main questions of these two experiments is: for the cost of the web-app code increasing by ~100KB (Icebird for parsing Iceberg files), do we get smaller data files (Arrow => Parquet, so probably yes) and maybe even faster parsing of the data files? The Iceberg R/W code (Icebird) will replace the existing Arrow R/W code, so will the JS-in-HTML code be smaller or bigger?