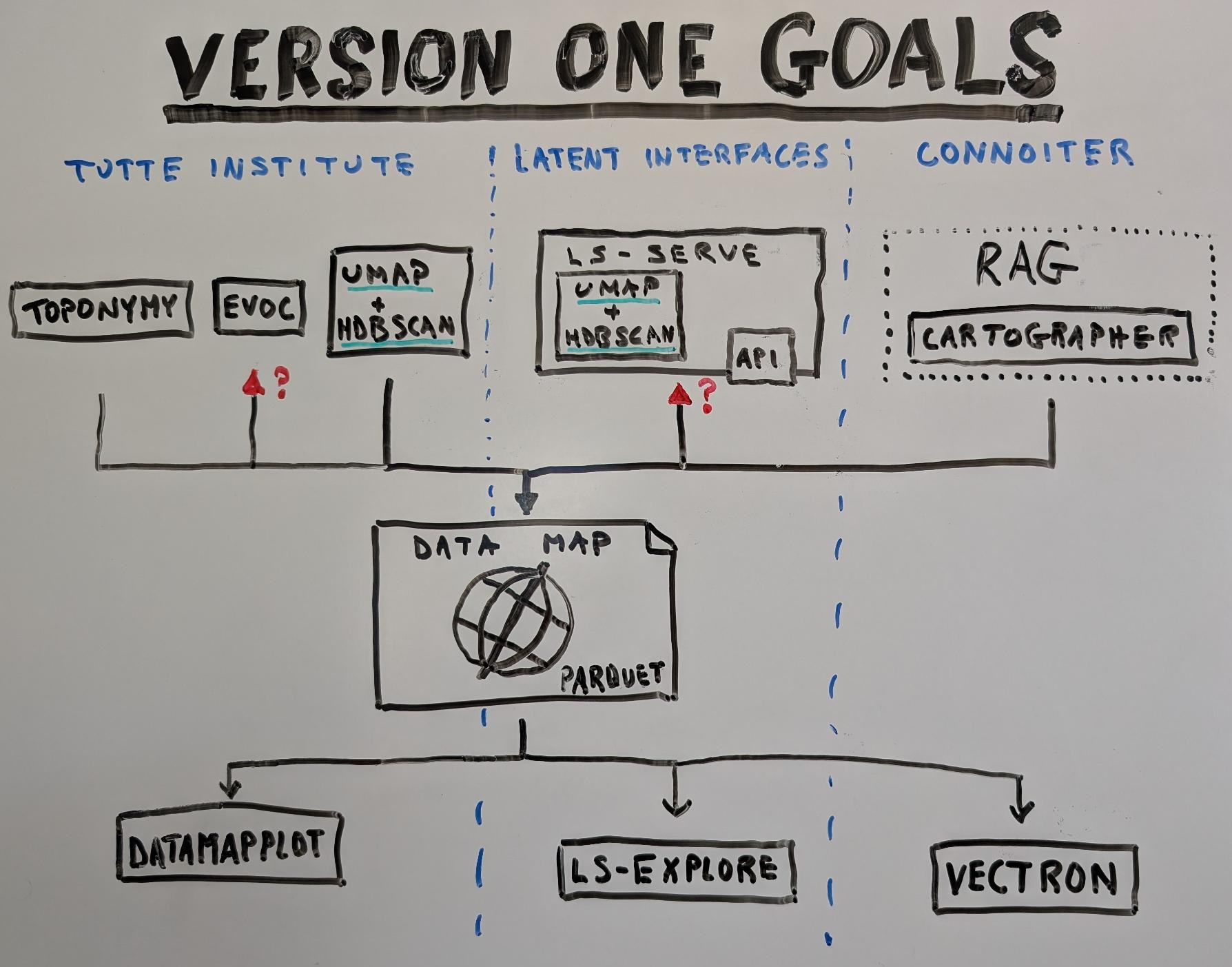
The goals for version one of the Data Map Schema project are intentionally simple:
- Harmonize DataMapPlot and latent-scope to use the same file format over the web.
- Connoiter implements is writing reference implmentations for read and writer
- Client: Vectron, a web-app that is a data map reader and visualizer
- Server: Dockerized RAG repo data mapper, a data map writer
The client and server reference implementations will be demo’d together in a RAG chat context. The chat UI will have a Data Map viz showing which parts of the RAG repository’s data is being included in the LLMs context window based on user’s query. This will work with some popular FOSS RAG codebase.
For Version One, out of scope is:
- 3D, nor higher dimensions
- Not multiple embeddings
- Anything besides text, no image nor other media
The goal is simply to come up with an interchange format which can be used by both Tutte Institute code as well as Latent Interface’s code. If those projects do not wish to be disturbed, we can simply crank out some transcoders that read their existing format and package the data up in the Apache Iceberg files for a Data Map Schema.
There are two main organizations cranking out liberally licensed open source data map machinery: the Tutte Institute and Latent Interfaces, and (conveniently) the latter uses machinery from the former. We are just trying to make those tools interoperable. And Vectron is simply Connoiter’s reference implementation of a data map reader.
Additionally, Connoiter is coding up new codebases for reference implementations of a client (read: Vectron) and a server (a containerized service which reads from RAG repositories and produces data maps) which can be used in a RAG backed chatbot system context, which can easily be integrated with FOSS RAG systems. Arguably this RAG stuff is new, and dropping it from the requirements would make Version One even easier to accomplish but Connoiter firmly believes the RAG context is worth guaranteeing from the start (for example, there needs to be a way to – over the wire – express a map subset for, say, selection or RAG retriever results listings).
(Bonus: we might as well seed a service API by starting with ls-serves’s existing API while we’re defining the data at rest format; but that IS a separate thing. Of course, such an API would obviously serve up data map schema’d info… so, blantantly relevant for standardization work.)