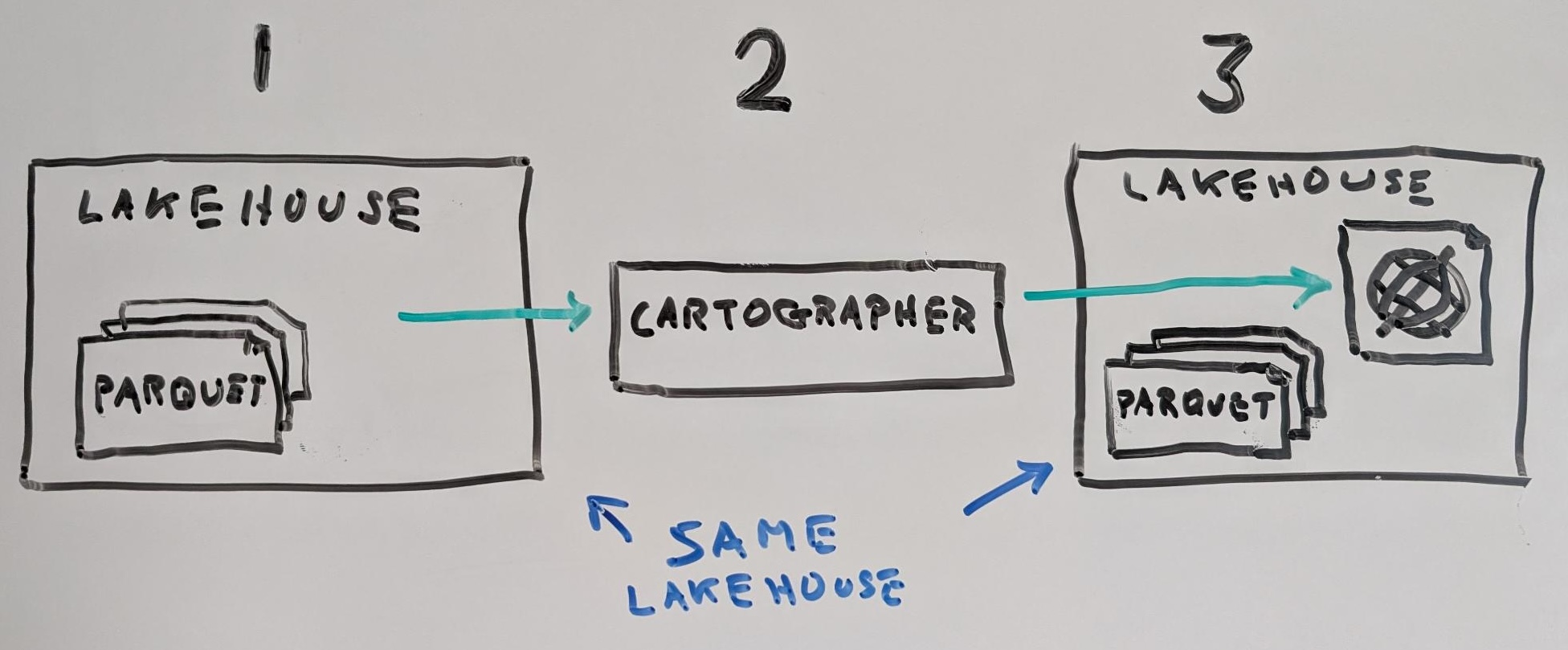
Why Apache Iceberg:
- Existing data map tools roughly aligned (already using Parquet)
- Allows for schema elovution which can be used to have an intentially limited v1 and then easily evolve to v2, v3, …xs
- Geo data types are new in Iceberg 3 (which is finalizing in summer of 2025)
- Based on GeoArrow
- GeoArrow parser for DeckGL: geoarrow/deck.gl-layers
- Useful data structures for representing objects on 2D maps
- Web-app context:
- Lakehouse context:
- Iceberg is a widely adopted format for data lakehouse
- Static files (over HTTP or local file system)
- DataMapPlot generates static file data map web apps
- “Lakehouse” is simply a fancy term form static storage (“object store”), plus a little DB machinery
- As of early 2025, Iceberg Catalog is now available as a mainstream managed service
- “The R2 Data Catalog in open beta, a managed Apache Iceberg catalog built directly into your Cloudflare R2 bucket.”
- We can expect the same from all the other cloud providers RSN
Network transport weight of various data stacks:
| Who | Weights |
|---|---|
| icebird + hyparquet | 85kb+10kb |
| DuckDB wasm | ~40MB |
| sqlite-vec wasm | 5.9 MB |
| LanceDB wasm | ??? |
Of course, just reading tables is not the same complexity of machinery as a SQL engine but perhaps such is overkill…